1. INTRODUCTION
For the last three decades, Objective Structured Clinical Exams (OSCEs) have been used for the assessment of clinical competence, medical knowledge, interpersonal, communication skills and professionalism as part of health professions education. Despite the apparent advantages of the professionalism OSCE (POSCE) over selfanswered questionnaires and work-based assessments, the psychometrics of this standardized exam has been the emerging topic in the literature. The reliability of the assessment is crucial, particularly when the aim of the POSCE is to provide the rationale for the judgment of medical novices’ professionalism, as is often the case in medical school assessments [2].
Particularly, some data on reliability of POSCE that determining resident’s acquisition of professionalism have been reported in several studies [4, 9]. Inter-rater reliability is one of the most concerned estimator of reliability of POSCE as making inferences from performance ratings requires the management of rater effects [1]. Findings from the past POSCEs showed inter-grader variability among different raters in grading same professional behaviors. Nonetheless, it is little known that the POSCE developed in Vietnam yields acceptable inter-rater reliability or less differences among raters. Therefore, the aim of this study was to investigate inter-rater reliability of the POSCE that was developed in the context of FM training in Vietnam.
2. METHOD
A POSCE was developed and conducted in Training Center of Family medicine, the University of Medicine and Pharmacy (UMP), Ho Chi Minh city. POSCE was administered at two different times, at the end of September, 2015 before the module of Counseling and Professionalism and at the beginning of November, 2015 in the FM orientation course.
Only faculty raters are recruited for the POSCE. In the pretest, 12 faculty members who were teaching faculty with both an MD and MSc in the field of FM with at least 5 years of clinical practice and teaching were invited. In the posttest, 12 raters in the pretest and 4 belatedly-recruited raters from the unit of Preventive Medicine(UMP) were invited. All raters had not experienced in rating professionalism OSCE before.
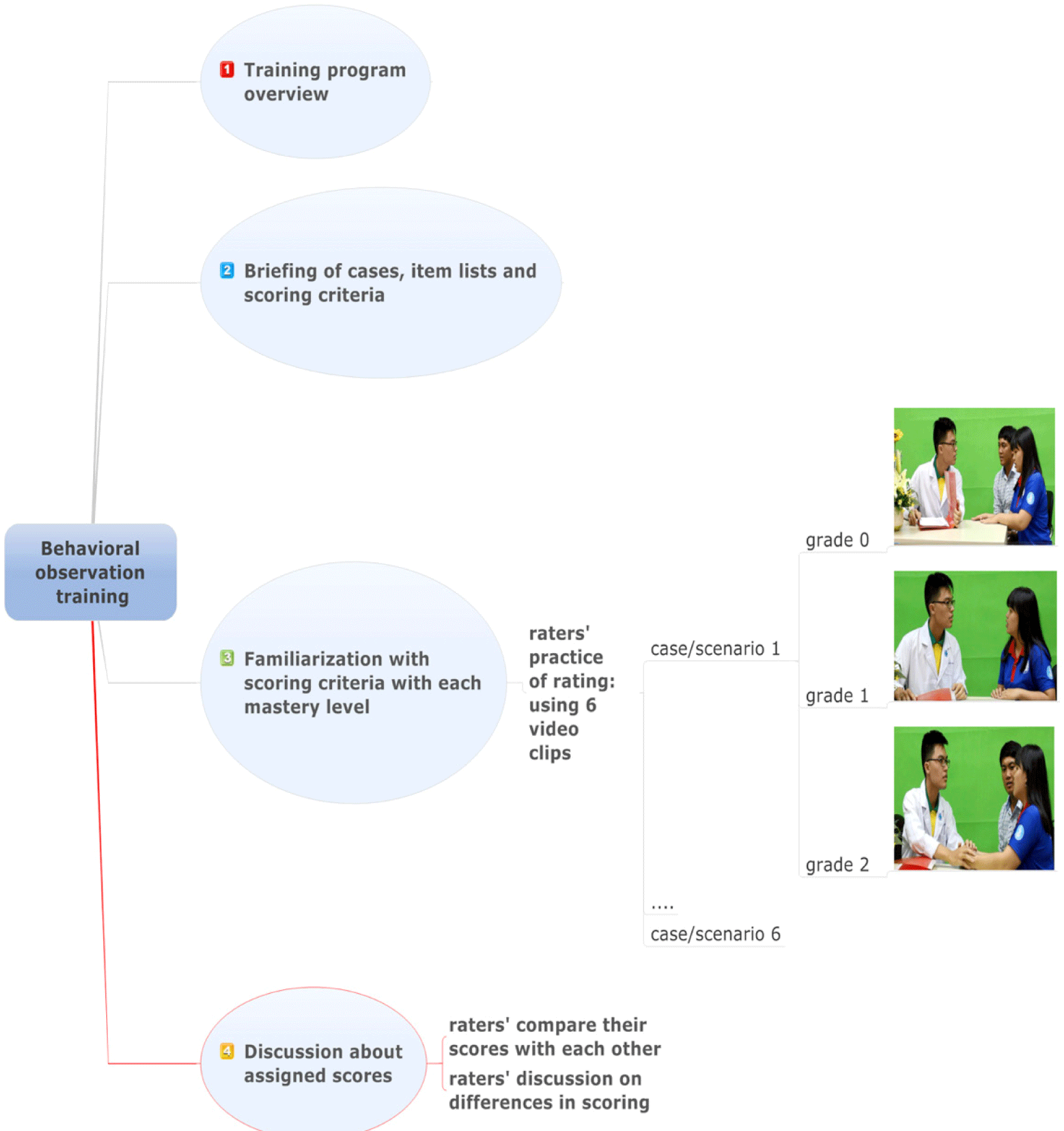
Raters’ training occurred in two different times, the former took place only for the 12 FM raters before the pretest and the latter was before the posttest for the 4 belatedly-recruited.
All candidates rotated through six stations. In each station, FM residents interact with a Standardized Patient (SP) who portrays a scripted ailment of a specific scenario. Two raters were arranged to grade performances in a station. It was customary that during the encounter, raters completed an evaluation form that contains marking items and the 3-point rubrics which pertained to these marking items. The grading rubric comprised 3 anchors: 2-meet standard; 1-borderline; 0-below standard. Behavioral descriptors were provided in each anchor of the rubrics.
Raters’ training was provided before pretest and posttest consisting of four steps as follows.
The raters viewed all scenarios and the scoring rubrics before training sessions. The author of cases and a content expert, Director of FM training center clarified any details of the cases, itemlists and the analytic rubrics.
Each group of raters participated in six one-hour training sessions for six scenarios. In each session, raters used the scoring rubrics to rate performances in three randomly-shown video clips. These clips intentionally demonstrated performances of three different mastery levels in each case, which was unknown to the raters.
After completing their scoring, the raters compared their scores with others’ items by items. Differences in assigning score in each item to the same encounter were discussed. Differences between raters’ and the expert’s scores in the same video clip were also discussed. This enabled examiners to achieve consensus regarding what constituted below-standard, borderline or meet-standard performance of certain behaviors.
Descriptive statistics of the scores given by the raters were calculated using SPSS 20. Inter-rater reliability was measured by the differences in mean scores between raters using paired t-test and inter-rater agreement using Pearson correlation coefficient.
All participants informed that their results will be analyzed for an evaluating study. They were also assured that their identities would be kept confidential. All participants gave verbal consent to join in the study. Their approvals were obtained on the exam days by having them sign on the registering paper before the exam.
3. RESULTS
Table 1 portrays the values of paired sample T-test for each pair of raters’ total scores assigning to one performance in pretest and posttest. No significant difference was found between raters’ mean scores in most pairs of raters in the OSCE pretest. Significant differences were found mostly in scoring the scenario of “Keeping confidentiality”, “Breaking bad news”, “Altruism” and “Self-awareness of limitation”. However, in the OSCE posttest, differences in mean scores between raters were found in eight out of twelve pairs. Notably, raters’ differences occur in all scenarios.
Table 2 presents the correlation between raters’ total scores. Moderate to strong positive correlation between raters’ mean scores were found in the pretest. Mean scores between raters in most pairs were strongly correlated, except in pair two and three where there is a positive moderate correlation between raters’ mean scores. In the posttest, mean scores between raters in the other pairs were strongly correlated. However, very weak correlation was also found between raters’ mean scores in pair two.
4. DISCUSSION
We found a strong consistency in grading and correlation between raters’ scores for residents’ performances in the POSCE. This would suggest that POSCE is able to consistently measure the candidates’ professional behaviors across different raters.
The finding from this study implied the important role of analytic rubrics in achieving high consensus among raters. When using holistic rubrics, raters are believed to use their intuition to rapidly decide which category a performance falls into [6]. However, raters still analyzed what they have observed and later, applied their personal experiences to make their assignment of scores since holistic rubric provides raters with a few of what constitutes a professional behavior4. This might increase subjectiveness, thus, cause more differences among raters in evaluation of professional behaviors [4]. Therefore, the analytic rubrics comprising case-relevant marking items and behavioral descriptors that guide the raters’ judgment might have lessened the raters’ bias and improved the inter-rater agreement.
Lack of consensus among raters might reduce the raters’ consistency in assigning scores [8]. This argument has been supported by this study. It found that most differences in total scores assigned by the pairs of raters, in which one of them was the belatedly-recruited for the POSCE posttest. Given that prior to the OSCE posttest, only these raters were involved in the training. Lack of discussion to reach consensus on how to assign scores among the former and the later raters might have caused raters’ gaps despite the similar training on grading professional behaviors.
This study suggests that analytic rubrics together with several features of raters’ training might improve the raters’ consistency. First, practical section should be included, in which raters are exposed to candidates’ samples of real performances to practice rating using the rubrics. Video clips can be an effective mean for practice if they clearly demonstrate performances at each mastery level on the rubrics. At the end of the practicing session, it is essential for all raters to compare their scores with the others’ for the same encounters and open discussions on the reasons for any discrepancies in scoring [8]. This can trigger a reaching consensus process, which is valuable in bridging the gaps between raters.
Nonetheless, this is a cross-sectional study. It is impossible to conclude to what extent those abovementioned factors influenced the inter-rater reliability. Moreover, there might be other factors that affect the inter-rater reliability such as raters’ professional backgrounds. Therefore, future studies should investigate multiple factors and their extent to which they affect raters’ consensus in rating in POSCE. Understanding these factors helps better manage the rater effects in POSCE and other performance-based assessments of professionalism.
5. CONCLUSION
FM POSCE can is able to consistently measure the candidates’ professional behaviors across different raters. Using analytic rubrics and features of raters’ training which facilitates raters’ practice of rating and discussion on discrepancies in scoring among raters might help improve the inter-rater reliability.